t
Here's a little background information about the design, implementation and hardware behind the aprs.fi site.
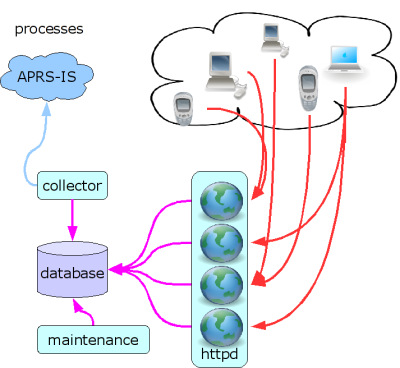
Components
The aprs.fi software consists of four main components:
The data collector and maintenance processes run on the primary aprs.fi server. The web user interface runs on multiple frontend web servers, and the real-time map engine runs mostly inside the web browsers of the users.
Although the software is very stable and resilient to problems in the operating environment, all components are run under a supervisor process which takes care of restarting them in case of an exception or a crash.
Localisation, content and presentation
The web user interface is based on a lightweight template engine. With the exception of unlocalised static information pages (like this one), the layout of the pages has been separated from the content, and the English strings have been moved to a database, so that they can be translated to other languages using a web-based translation tool. Most importantly, the content and layout has been mostly separated from the application code, so that the look and feel can be customised without modifying the software. There are separate layout templates for mobile devices, and it would be straightforward to implement a new look for a new class of devices.
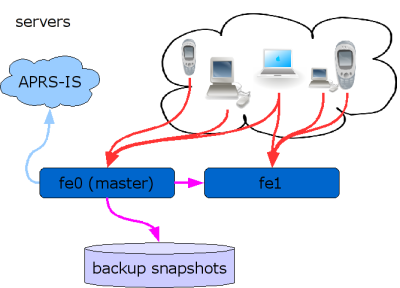
Scalability and availability
aprs.fi was initially implemented as a service which only ran on a single server, but as the popularity of the site has increased, it has been improved so that it can be run distributed on a number of servers. Distributing the system on multiple computers improves the availability and the performance of the service.
aprs.fi currently runs on three servers. Two act as a load-balanced pair of web frontend servers, and the third one is a data backup system. One of the frontend servers acts as a primary data collector, connects to the APRS-IS, receives data, and stores it in the database. Updated data is immediately replicated to the other servers by the database backend. When an user surfs to the web site, the request is served by one of the frontend servers. When the user clicks a link to get the next page, it might come from another frontend server.
There are a couple of shortcomings in the current setup: The system is currently only configured with automatic failover for the web service. If the primary server fails, position data collection will be down, until the secondary server is manually promoted to act as the primary server. Also, because all of the servers currently store a copy of all data, adding more servers will not improve the system's data storage capacity - it only improves it's availability and the performance of the web service. Adding support for more position transmitters, or increasing the storage time or detail of position data, requires adding disks to all of the servers. Some work has been done to support partitioning the service so that a subset of the servers would handle a subset of tracking devices, but it cannot be utilised or completed until at least 3 physical servers are used.
Backups
Taking consistent backups of a large and active database without stopping it for the duration of the backup is fairly tricky, and while it can be done, it does have a performance impact. So, aprs.fi has a dedicated backup snapshot server, which doesn't serve any users directly - it is only used to take backups of the live database.
The database service on the backup server is first stopped, a filesystem snapshot is taken, and the database is started again. After it's been started, it will catch up with the primary server, sequentially replicating all updates which have been received during the backup. The compressed backup snapshot is then made from the consistent filesystem snapshot.
Complete snapshots are created once every two days. In addition to these, the database transaction logs are stored as long as the snapshots. If the database is corrupted by a bad transaction, it is possible to recover the complete database snapshot which was last taken before the corruption, and the transaction logs can be used to replay all database operations done before and after the corruption, so that most data can be preserved, even if it takes some time before the corruption is noticed.
The backup server is located 9 kilometers away from the live web servers, in the next city. If a fire would destroy the primary hosting site, the backup will still be available.
Monitoring and alarms
The availability of the service is monitored using Nagios. The alarm system verifies separately that all the required components of the system are operating correctly, and also does end-to-end tests from the end-user's point of view.
Alarms are sent using both using POCSAG pager messages on the 2-meter amateur radio band, and as SMS messages with a GSM mobile phone which is directly connected to the testing host, so a network outage will be communicated, too. The service is currently run by an individual, so 24/7 operation can not be guaranteed. This is only my hobby, after all.
Performance history data is also collected in RRD databases. This provides a longer-term view in service latency, database size and host performance.
Open Source and development environment
The software has been implemented utilising Open Source components where possible. The frontend servers run the Linux operating system, the data is stored in an Open Source SQL database, and the scripting languages used are freely available. The software itself is not Open Source and not available to outside developers, but some of the used Open Source components have been improved during the development, and the improvements have been given back to the community.
The software is written in popular scripting languages, and it should run unmodified on all modern Unix platforms, although it has only been tested on Linux and Solaris.
Server hardware
The service runs on proper rack-mounted server hardware. The servers have mirrored (RAID1) disks. If a single disk of a server fails, the server will continue to run happily. The servers also have ECC memory which protects them against single-bit errors caused by background radiation.
frontend servers 1 and 2
- 2* Intel Xeon quad-core (E5450) 3.00 GHz, 12 Mbytes cache per chip - 8 cores total per server
- 32 Gbytes RAM memory with ECC
- 2* 750 Gbytes SATA disk, hardware RAID10, 750 Gbytes usable capacity
backup snapshot server
- 1* Intel i7-6700 3.40 GHz, 8 Mbytes cache, 4 cores
- 32 Gbytes RAM memory with ECC
- 2* 4 Tbytes SATA disk, software RAID1, 4 Tbytes usable capacity
Network and hosting infrastructure
The servers are all hosted at a commercial-grade hosting site with cooling, uninterruptible power supplies (backup batteries), a diesel backup power generator, and a halon gas fire suppression system. The site has redundant network connections to multiple Internet providers, and a very stable local network with Cisco routers and switches.